Architecture#
Our intended architecture for this implementation relies on a Kubernetes cluster that manages a collection of microservices, some for the explicit requirements of the application and others to glue these together or make the whole of it more scalable. The result is a design with which one could easily mitigate the most obvious bottlenecks, both in terms of processing time, and availability and platform reliability.
Our technology stack includes Kubernetes and Docker for deploying microservices written for the most part in Python with Flask, RabbitMQ (also deployed inside de Kubernetes cluster) for loosely coupling services, a MySQL DB for keeping track of users and their permissions, a separate MySQL DB for tracking records from the uploaded CSV files, and a MongDB cluster with GridFS for storing the uploaded CSV files.
Let us look at an overview of the architecture.
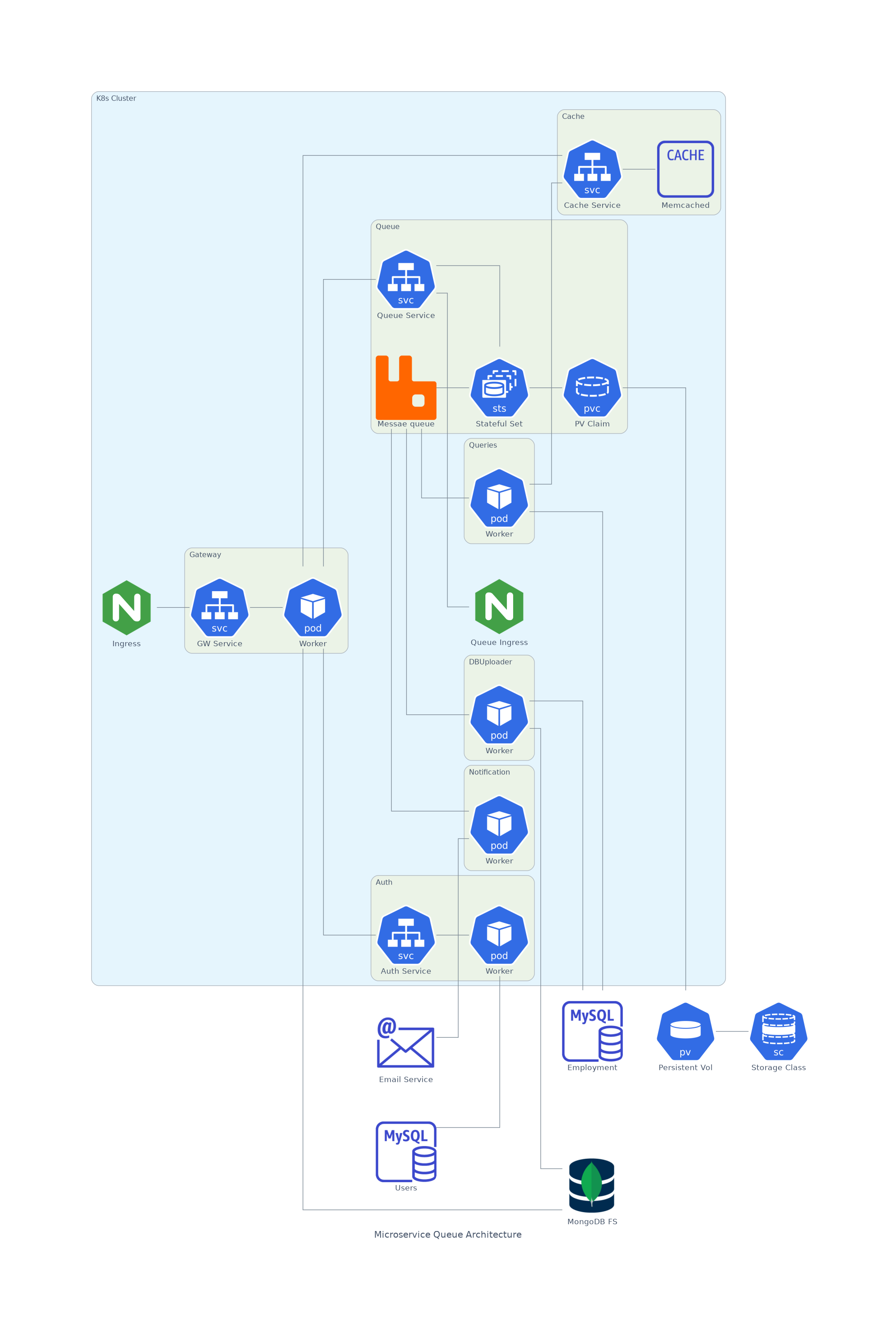
This diagram is built using the Diagrams.py package and might not be a true representation of the architecture of the deployed application. It was made with a reasonable amount of attention to detail. You can review the Python code that generated this diagram by viewing the Markdown source of this page.
Because this is a microservice architecture, every major component of the application is deployed with its own service and deployment Kubernetes resources. Regular traffic to the application URL gets routed to the Ingress resource and handled by the gateway service which exposes all of the application endpoints.
To read in greater detail how each of the services works internally, move on to Services and APIs.
Application flow#
Authentication#
Any interaction with the application begins with a login POST request that gets handled by the gateway service. This request’s contents get forwarded to the auth service which, if the user submits the proper credentials, would generate and return a temporary JWT token with which the user can authenticate for all other requests. The auth service queries a users SQL database external to the cluster but within the security group with no external traffic allowed.
To perform all other tasks such as uploading a CSV file or querying the employee database, the user needs to have already authenticated and needs to include their JWT token with every request.
CSV Upload#
If the user sends a POST request to the CSV upload endpoint with a proper JWT token, the gateway service will then upload the CSV file to the MongoDB instance (or cluster) and send a message to the queue service, which loads it onto the RabbitMQ instance (upload queue). Within the Kubernetes cluster the dbuploader deployment is always running (not as a Flask web server) and consuming messages from the upload queue. The dbuploader deployment will download the CSV file from the MongoDB instance and process it. If this process fails by no fault of the user, the message does not get removed from the queue and will remaine until the operation is succesful. Once the CSV gets processed and submitted to the employment SQL database (also external to the cluster but within the security group), the dbuploader deployment submits a message to the RabbitMQ instance (query queue).
The CSV file remains in MongoDB.
Query System#
The queries deployment is always running (not as a Flask web server) and consuming messages from the query queue. The queiries deployment will perform predetermined queries from the employment database every time it takes hold of a new message on the query queue, and will replace the objects through the cache service. If this process is succesful, the message gets consumed and a new message is sent to the notification queue.
If the user sends a GET request to the queries endpoints with a proper JWT token, the gateway service will respond with the matching object from the cache service.
Notification system#
A notification deployment is always running (not as a Flask web server) in the cluster which consumes messages from the notification queue. Same as with the dbuploader deployment, the message will not be removed from the queue until the notification deployment succesfully connects to the SMTP server (hosted outside the cluster) and sends an email with the result of the CSV upload operation.
Caching system#
A cache service can take GET requests from the gateway service and POST requests from the queries deployment. This service reduces load on the employment database.
Queuing system#
The queue service connects to a statefulset that runs a single RabbitMQ pod. Because we want to keep these messages in the queue as they represent the state of our application, we tie the statefulset to a persistent volume through a persitent volume claim. Of course, this data is written to a disk outside of the cluster and could easily be replaced with a more robust storage solution.
The queue pod holds three queues:
upload queue: keeps track of pending CSVs to upload to the
employmentdatabase. Messages get pushed to the queue by thegatewayservice and consumed by thedbuploaderdeployment.query queue: keeps track of pending updates to the
cacheservice after new data enters theemploymentdatabase. Messages get pushed by thedbuploaderdeployment and get consumed by thequeriesdeployment.notification queue: keeps track of pending notifications to the user that requested an upload. Messages get pushed by the
queriesdeployment and consumed by thenotificationdeployment.